2月4日,第35届人工智能国际会议AAAI在线召开。开幕式上,组委会揭晓了本届会议最佳论文奖(Best Paper Award),共三篇论文入选,其中首篇最佳论文由北京航空航天大学计算机学院、北京航空航天大学大数据与脑机智能高精尖创新中心博士生周号益(第一作者)、彭杰奇、张帅和李建欣教授(通讯作者)联合UC Berkeley大学仉尚航博士、Rutgers大学熊辉教授等团队所斩获,论文题目为《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》。AAAI是世界人工智能领域著名国际学术会议之一,本届会议提交论文数量达到9034篇,再次创下投稿量历史新高。这是中国大陆42年来第二次、时隔近十年再次获得人工智能领域AAAI最佳论文奖项。同时,北航计算机学院硕士生郝雅茹和指导教师许可教授联合微软亚洲研究院董力、韦福如完成的论文“Self-Attention Attribution:Interpreting Information interactions inside transformer”获得AAAI最佳论文Runners Up奖。

面向长序列数据的Informer网络结构示意图
长时间序列分析预测一直是人工智能基础理论研究的难点,对工业健康维护、疾病传播预测、网络安全分析等关键领域具有重要作用。获奖论文指出“传统循环神经网络因误差逐层累积”已不能满足长序列数据分析的需求,并首次明确了Transformer神经网络架构对长序列问题建模的重要意义。该架构的核心优势是构建了自注意力机制来捕捉跨长度的前后相关性,但其伴随的重大挑战是自注意力操作具有随输入长度的二次时间复杂度,无法适用于长序列输入和输出。据此,该论文突破了传统自注意力的计算复杂度限制,提出一种全新的从概率角度进行自注意力矩阵稀疏化的模型ProbSparse Attention。该模型可以允许以非启发式的方式对自注意力计算进行长尾显著性分析,摘取长序列中重要的前后相关性对,可以依采样方案将计算复杂度降低至对数线性复杂度,令ProbSparse自注意力满足长序列分析的建模要求。同时,该论文还提出了注意力蒸馏机制来允许构建更深的长序列堆叠模型,同时通过生成式解码来实现长序列单次前向输出。这是首次在长序列问题上运用Transformer神经网络架构,依靠所提出的可分析稀疏化、注意力蒸馏和生成式解码组成Informer网络结构,可以在同样硬件限制下显著提高序列分析任务性能,为解决长序列问题提供了一种全新的解决方案。









 北航校历
北航校历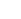 校园地图
校园地图